總統選舉期間,民調紛紛出籠,但許多數字上的使用或解讀偏誤,導致最終結果喪失知識上的意義。本次《看懂民調》專欄邀請吳統雄教授,綜合評估封關後的 15 家民調,並藉此觀察出真實趨勢與民調差距。
總統大選結束之今將近 3 個月,民調議題成為本次選舉的討論焦點,最終結果出爐後,大家也紛紛討論「哪家民調沒有穿褲子」,全民瘋統計的盛況,也是台灣選舉史上首見。
本次《看懂民調》邀請世新大學資訊管理系前主任吳統雄,他是國內「統合分析」的專家,也是最早開始推廣統合分析的教授。他將以本次總統大選的 15 家封關民調作為實例,介紹並深入分析。
什麼是統合分析?
「統合分析」是適於綜合評估各家民調,相對客觀的科學方法之一。
集合多家坊間調查,只要沒有故意做假、樣本具備分散性,在候選人之間真實差距很大、且大於作業誤差時,統合分析有可能觀察出真實趨勢。

▲ 民調統合。(圖/翻攝 Pexels;示意畫面)
統合分析主要程序有三:選擇納入「統合分析」的資料、標準化資料、選擇分析方法。這 3 個程序,又分為基礎級、與進階級方法。本文為科普目的,故介述基礎級程序。
統計之可以推論預測,最重要的 2 個前提是:具備「隨機/等機率」樣本、與達到最低樣本數以上。
在真實社會中,許多環境條件不容易取得「隨機/等機率」樣本,尤其當前生態,所有坊間民調都不是「隨機/等機率」樣本。
統合分析便是選擇「人為誤差較少」的案件,調整使其「測量標準盡量接近」,成為可大致合并觀察,達成「以擴大樣本的原理」,而提升可推論預測性。
統合分析的三大篩選原則
本次將納入坊間民調公司所做的總統大選封關民調,不過,這些資料尚須經過一些處理和篩選,才能知道是否可以逕行採用。一共分為三大步驟:
1. 選擇納入的資料
統合分析首先要選擇納入分析的資料,再分為:納入哪些民調公司、納入哪些報告。納入哪些民調公司的原則有二:沒有故意做假、樣本具備分散性。
坊間無法到達樣本具備隨機/等機率性,但要至少具備「分散性」,尤其在採用 RDD (Random Digit. Dialing)方法時,不得發生「整群」號碼都不在樣本庫中的情形。
如果民調公司沒有持續增加新樣本、與定時檢查過濾既有樣本,甚或開始建立的來源樣本就有系統性偏差,如來自某個團體的會員樣本,則此樣本庫就存在「樣本分散性」低的事實,即使不作假,也會自然產生偏差。
樣本分散性有測試機制,但須要到各民調公司做現場測試。故在本次範例中,暫略過不論。
2. 樣本數與研究方法考量
納入民調公司哪些報告?有樣本數與研究方法條件的考量。
臺灣隨機/等機率調查的最適樣本數,應該是 1500 至 3000戶、樣本 4500 至 9000 份。不過,當前坊間民調都是 1067 個左右。這是市場「民調套餐」的積習,所以我們把所有民調套餐都納入。
研究方法方面,有人爲誤差嚴重的不應列入。研究方法會產生的誤差很多,本專欄已陸續介紹多項。本範例將所見的 15 家民調全部納入分析,最後也可作為相互印證。

▲ 民調資料在解讀前須先標準化、表格化。(圖/翻攝 Pexels;示意畫面)
3. 資料標準化
如何標準化資料?哪些資料必須標準化?實務上如何標準化?有以下重要觀念:
- 資料庫化/表格化與欄位
- 不明資料的解析
- 可標準化之「決策支援參數」
- 標準化百分比
民調資料若欲作深入分析,都必須進入資料庫,首先就是先表格化。
原始資料表——不明資料要如何解決?
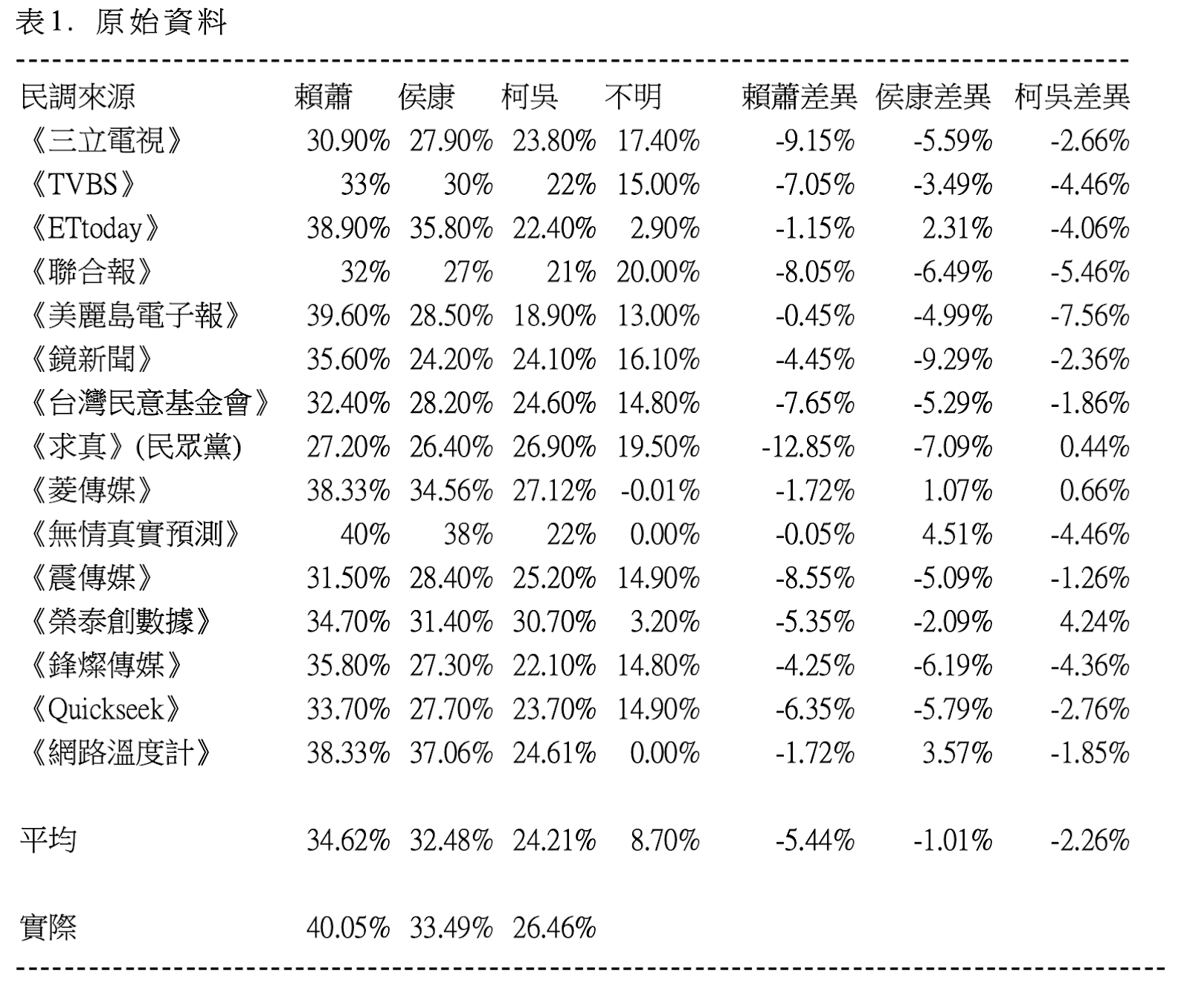
原始資料表如下圖(表 1)所示。
坊間媒體比較「封關民調」的通俗文章很多,都是比較「原始資料表」。但許多家的數字加總後都不是 100%,另有「不明資料」沒有處理,這是不正確的。
所以,必須整理出完整欄位。整理發現,「不明資料」最高達 20%,平均為 8.7%,故嚴謹的研究必須予以處理。
不明資料部分,其來源有三種:未決定者、不投票者、投廢票者。以下將逐一解析,其各自的解決方法:
1. 樣本數與研究方法考量
未決定者其實就是誤差的一種。在單一席次選舉中,很少人在選舉前 8 周還沒有決定,只是不願告知訪員。
生物與人類行為現象,經常出現這類無法直接得知,但可以「間接/模式測量」而得知的問題。
譬如「健康」難以得知,但我們經由間接測量:體溫、血壓、血醣、肝指數…,再建立一個分析模式,就可估計健康的程度。選舉也是一樣,以後另文再介述。
2. 投票率:決策支援參數
減掉不投票者,就可估計投票率,這是個非常重要的「決策支援參數」。譬如「體溫」的正常參數在 35 至 38 度之間,如果超出此區間,就是可能有疾病的指標。
以選舉來說,每次候選人的得票都不會一樣,但總統選舉存在投票率在 65% 至 80% 的參數,如果是做「隨機/等機率」調查,在診斷是否到達隨機標準,就十分重要。
3. 廢票:微小值可不計
科學有一個原則,就是微小值可不計,本次廢票率僅為 0.7%,故可不計。
此外,觀察原始資料表,我們發現:當前民調公司都宣稱誤差為 ±3%,但除了 1 家之外,其他全部至少有 1 個兩兩比較超過 ±3%,亦即宣稱與結果均違背,同時,差別很大,也造成分析判定的困難。
我們把實際得票率放進表中後,我們發現是拿一個四欄表,去比三欄表,在邏輯上是不通的。
直接將各原始資料總加後平均,這就是「願賭服輸」模式,民進黨便一直使用這個模式。若是採用這個方法,只要請 3 位工讀生就好,不需要什麼專家分析。
這次選舉各候選人之間差別都很大,這麼做影響不大。如果差異很小,就非常容易出問題,故在知識上,必須先標準化後再行比較。
標準化資料表——需先將原始民調百分化
各家民調都是在做「測量」,來源不同的分數總加,並無知識上的意義,如同跨校成績比較必須標準化。
許多父母因為子女升學,逐漸瞭解各校評分方法、文化不同,如果將各校原始成績,拿去做跨校比較,誤差很大,所以已認知成績必須標準化。舉一反三,民調之間的比較,也應如是。
標準化的方法很多,其中易於瞭解的,就是標準化百分比,使候選人的總加為 100%。標準化資料表則如下圖(表格 2)所示。
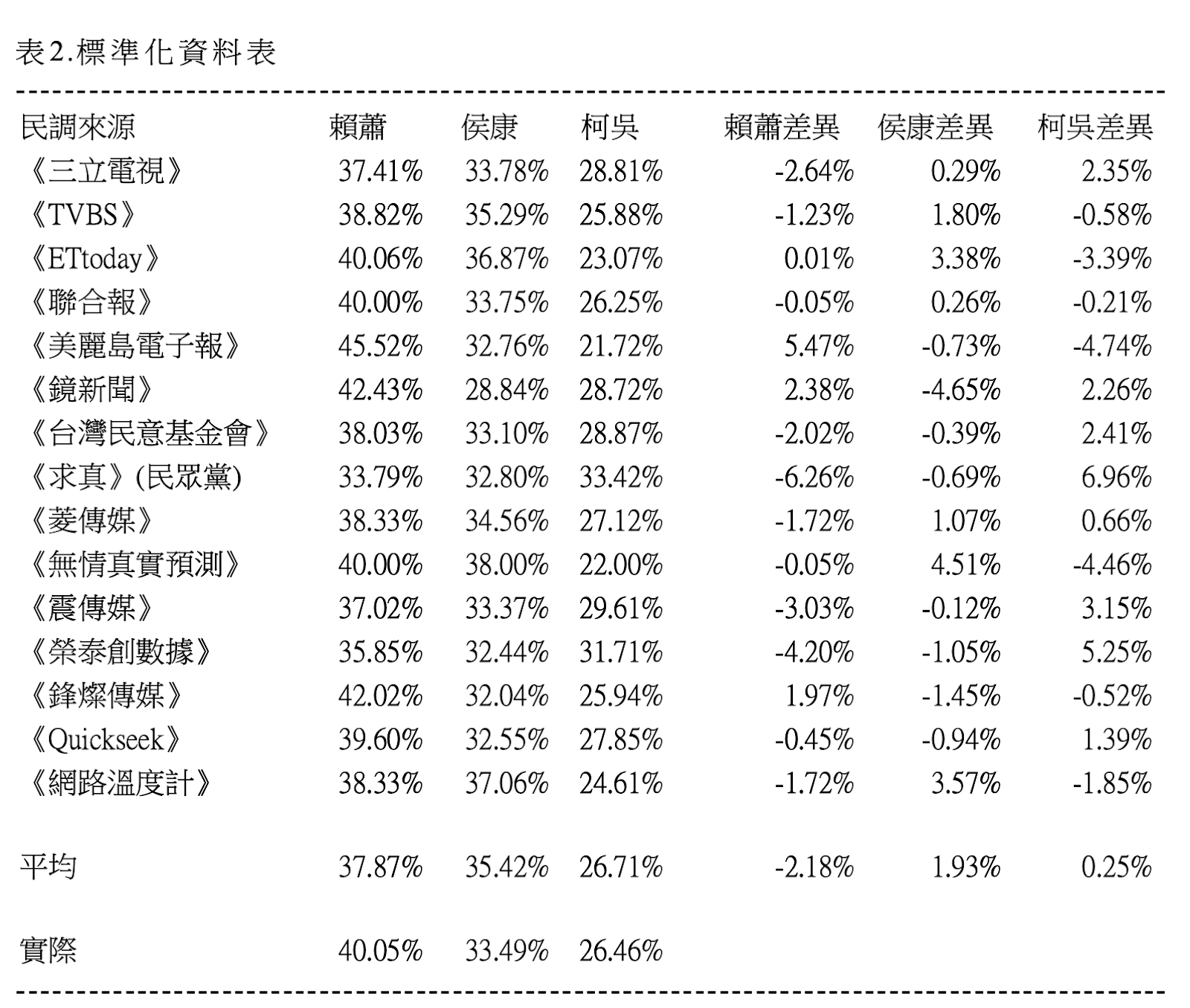
我們發現,3 組候選人的平均資料與實際資料,全部縮減到 ±3% 之內,經過以上程序,資料之間的差異縮小了,也增加我們判定的信心。
在標準化表中,只有 3 家:《求真》(民眾黨內參)、《美麗島電子報》與《榮泰創數據》,與實際差別比較大。前 2 家本專欄都曾經做過分析,討論過其研究方法的問題。本專欄另有一個專題,介述「手機簡訊」不是個適當的選舉調查方法,而《榮泰創數據》是其中唯一採用手機簡訊者。
因此,「統合分析」不僅可協助觀察出真實趨勢,也可反過來讓我們發現研究方法有問題的機構。
核稿/責任編輯:宋思彤
【作者介紹】
吳統雄
臺灣民調創始人。世新大學資管系創系主任、曾任教於臺清交、與美國喬治亞理工等,是喬治亞理工 Adoption Modeling 研究團隊首席。
歷任聯合報系資訊中心副主任、神通機構高階主管、日商科技公司總經理,因創辦電腦統計民意調查而獲得國家金鼎獎。
他是第一代民歌手,擔任過廣電主持人,發表過唱片,是長期公共評論人。網站與電郵請見連結。