民眾黨 17 日公布總統大選內參民調,民眾黨柯盈配攀上第二,支持度為 27.2%;政黨支持度則與民進黨不分上下。但學者認為,民調報告中有部分數據加權方式錯誤;同時,部分選項測出樣本數為零,也被學者點出「測量與分析基本功不足」。
【民調摘要】
民眾黨 17 日公布總統大選內參民調,民進黨賴清德、蕭美琴組合為 31.5%,第二名為民眾黨的柯文哲、吳欣盈組合為 27.2%,第三名是國民黨的侯友宜、趙少康組合,為 25.8%。內參民調顯示,民眾黨目前居於第二名。
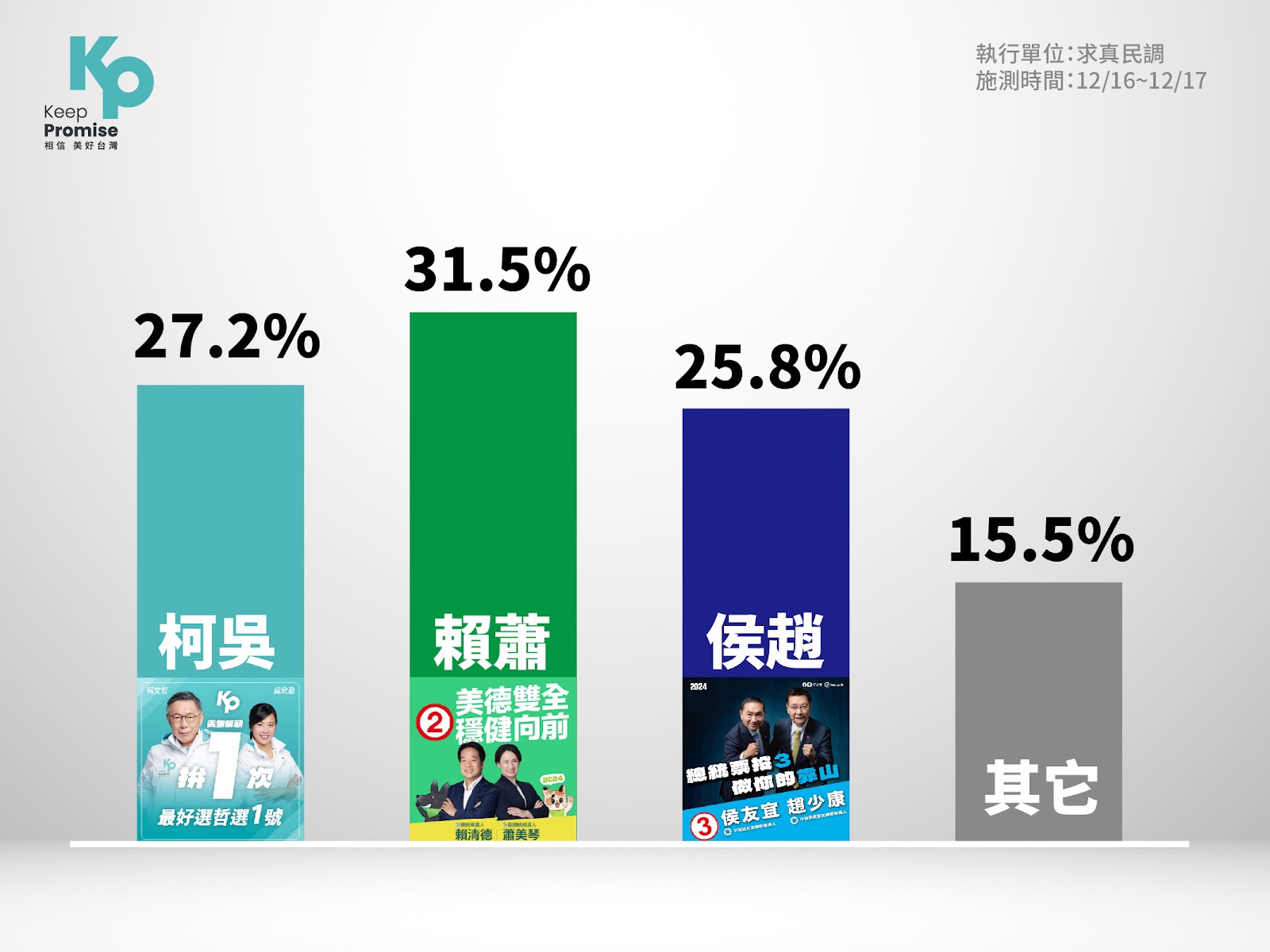
▲ 求真民調指出,柯盈配目前居於第二名。(圖/民眾黨提供)
政黨支持度方面,國民黨以 27.9% 居冠,民進黨與民眾黨分別以 24.8% 與 24.6% 居於第二及第三名,結果在誤差範圍內。本次民調透過市話 2/3、手機 1/3 進行抽樣,同時公布詳細的民調報告數據。
【專家分析】
本次〈看懂民調〉專欄,邀請世新大學資訊管理系前主任吳統雄,解讀民調的三大爭點,並進行詳細解析:
本案無法脫離「資訊系統綁架困境」,其報告之「抽樣誤差」不僅是錯的,對採用替代樣本,而形成的非隨機/非等機率樣本而言,根本是無意義的(請參見 2022.08.08《看懂民調》對「抽樣誤差」的解說)。
一般坊間調查均不能夠推論為代表全臺民眾的意見。但如果沒有作假,且其樣本庫夠大、仍具分散性,本案可以代表所訪問到的樣本 1225 人。惟本案採用了許多坊間民調共同的誤解方法、產生了許多人為的誤差,而其主觀配置方式,無法排除更擴大誤差。
爭點一:民調數據加權過大
本民調在加權過後,支持度的改動相當大,謹列出下列四點問題:
-
柯盈配的支持度,在加權後升高了近 1.4 倍(若單獨看手機則是 1.45 倍),其他兩位候選人加權後支持度都減少。
-
政黨票及政黨理念也有類似問題,民眾黨被加權了 1.3 倍,其他兩黨加權後支持度都減少。
-
年齡部分,20-29 歲在市話跟手機,都加權超過兩倍以上;30-39 歲也加權超過 1.5 倍。
-
性別部分,女性手機族的調查數據也放大了 1.3 倍。
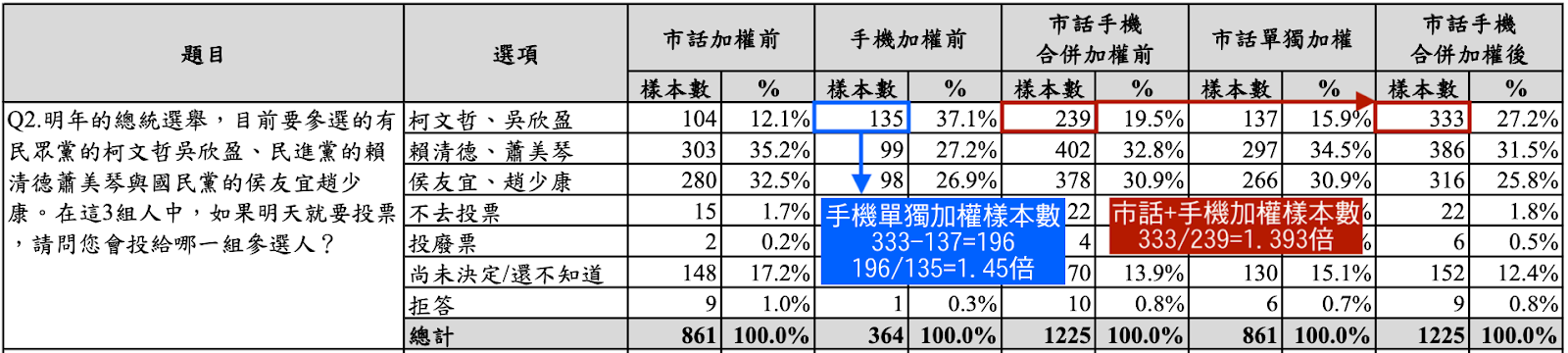
▲ 柯盈配在加權前後的數字比較,數字加權後被放大了 1.39 至1.45 倍。(圖/翻攝求真民調報告;宋思彤後製上字)
採用沒有因果關係的「加權法」,只是美化數字,可能反而擴大誤差。
當前各坊間民調多採用 RDD 法、亦即尾數隨機號碼法。這個方法是對的,但會大幅提高一時找不到受訪者的比例。
坊間民調有營利、成本的考量,不願持續追蹤原始、隨機等機率樣本,於是不斷更換樣本,會造成樣本的人口資料,和母群(或稱母體)產生很大差距。
所以,這些民調公司再採用「性別、戶籍、年齡」加權,不論是否存在選舉預測目的,只有美化數字的效果,不能增加推論性,反而有擴大誤差之虞。
「加權法」必須是加權項目,為應變項的因果/關聯自變項。譬如:要預測燒開水所需時間,若我們各式水壺與瓦斯桶樣本不足,但根據已有樣本的「水壺容量」、「耗瓦斯量」加權,則可經加權,正確預測各種燒開水時間。但如果我們以「水壺廠牌」、「瓦斯桶顏色」加權,則毫無作用,只是美化數字,可能反而擴大誤差。

▲ 以燒開水所需時間解釋加權的用處。(圖/部分圖片翻攝今周刊;吳統雄老師資料提供;宋思彤製表)
國內外長期選舉研究,早已證明「性別、戶籍、年齡」和投票並無因果/關聯,用此 3 項加權,較可能都是擴大誤差。
普遍的民調實務上,會對年輕受訪者加權,其直覺原因是:中外民調自始都有「在家男性偏少、年輕人偏少」的現象。所以就將樣本的性別、年齡,依據普查資料加權。但長期研究顯示,25歲以下年輕人投票的比例本來就比較低,而去投票的通常意識型態比較鮮明、政治態度積極度超過同儕。
也就是說,願意回答選舉民調的是年輕人中積極的少數,但經過加權後,他們變成假的多數,更提高了年齡層的影響力,造成巨大的扭曲。
舉一個假設的簡化例子如下:
若總選舉人為 100 人,投票率為 69%(參酌歷年投票率),按人口普查資料平均分為:高、中、低 3 層,則下表中的數字正好等於百分比。
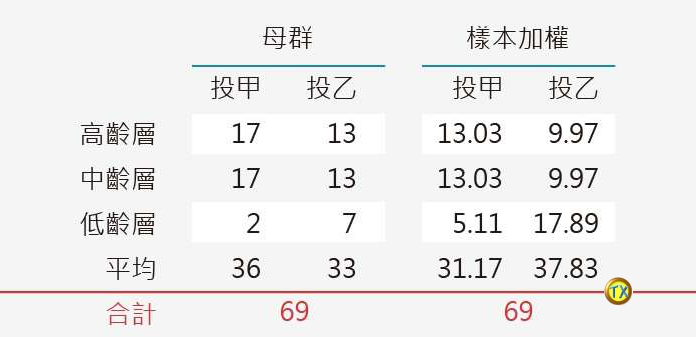
▲ 不同年齡層、母群與樣本加權後數據。(圖/吳統雄老師提供)
若母群、即真實結果如左欄,甲候選人實以36:33,勝乙候選人。但在坊間民調,由於視覺上發現「低齡層受訪者偏少」,於是主觀認為要把年輕人加權如右欄,變成甲候選人反以 31.17:37.83,落後乙候選人。
所以,加權很有可能造成失真,而本案宣稱「多重反復加權」,更有可能擴大多重失真。
爭點二:有利於民眾黨的「無意不真」數據
民調是否「故意作假」需要嚴格的證據。但因只會操作電訪系統,不瞭解調查的理論與方法,而產生「無意不真」的情況則比比皆是。
影響調查可推論性的第一個因素是:樣本隨機/等機率性。本案與一般坊間民調的更換樣本、加權…都扭曲了樣本的等機率性。
本案與其他坊間民調的不同,還源於市話與手機樣本配置的不同。
手機興起後,用手機訪問到年輕人的機會較高,所以 2012 年之後的民調必需開始採用「手機輔助調查」。不過,坊間民調並不瞭解「輔助調查」的意義與方法,於是直接採用市話號碼加手機號碼。但是,市話號碼和手機號碼是 2 個「重疊母群」,相加必然造成破壞等機率性、且無法估計的錯亂,所以根本不能相加。

▲ 手機調查與市話調查,學理來上說應做兩個不同母群的調查。(圖/翻攝 Gadgetsin;示意畫面)
若要採用這種作法,應該是要做 2 個不同母群的調查,而手機目前不存在完整母群,也尚無法以 RDD 法(尾數隨機號碼法)解決。一般坊間民調市話與手機樣本的配置是 5:5,也就是 2 種調查的樣本各減半,樣本少則誤差大,相加法就是在擴大誤差。
而本案的市話與手機樣本的配置是7:3。從上節的「加權表」,我們可以看出,原始真實的數字若愈小,則不當加權後,造成的誤差愈大。本案以較少的手機數字去加權,必然產生比其他坊間民調更大的扭曲。
因此,本案最有可能還是委託人與執行人對調查與統計的不瞭解。如果是故意作假,許多前例顯示,不會做這樣還有相當程度的資料交代。
爭點三:測量與分析基本功不足
在本次民調報告中,能夠見到許多關於「零」的數據結果。
例如:在第 5 題詢問「民眾是否會去投票」時,投廢票、拒答的調查結果均為 0,意即完全沒有人選擇這個選項;第 4 題、第 7 題皆有這種情形發生。
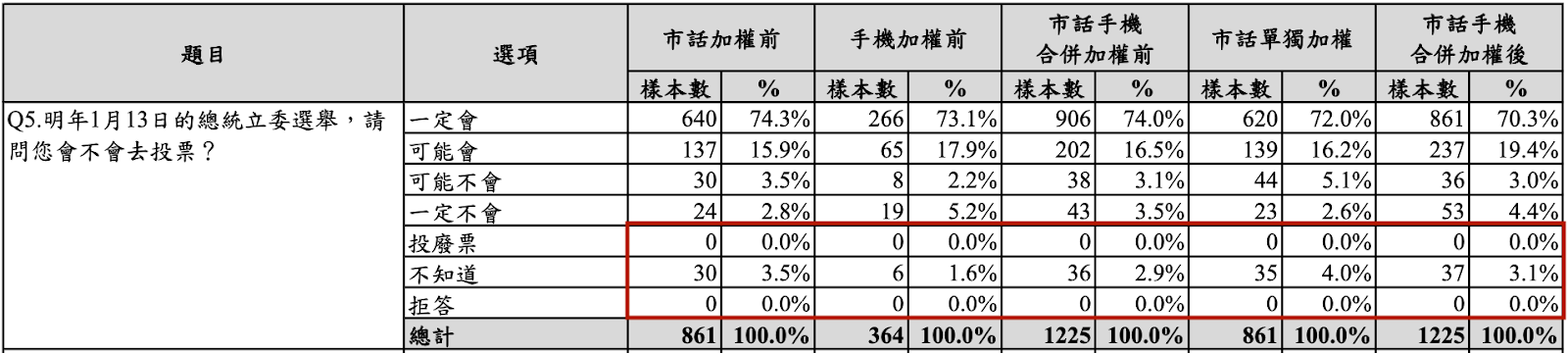
▲ 投廢票、拒答人數,無論透過手機、市話調查皆為 0。(圖/翻攝求真民調報告;宋思彤後製上字)
影響調查可推論性的第二個因素是:樣本數。
一般性調查如市調,若須具備可推論性的「最適樣本數」參數值為 1500;而敏感性調查如選舉預測,「最適樣本數」參數值為 3000。如果是隨機/等機率樣本,並不需要超過參數值;若是非隨機/非等機率樣本,就只能多多益善,且還不見得正確。
當前坊間民調,大多以 1067 樣本為基準,其實是業務上「民調套餐」普及化的結果,正如各快餐店都推相同的排骨套餐。就統計上,這個套餐的樣本數偏低,在當前又分為市話與手機樣本,等於 2 個調查樣本數更大幅減少。
在樣本數偏少,而選項又很多時,無法排除會出現「0」的數據。
在統計上有一個重要知識:在「交叉表」中的任一「細格」,不得為「0」、不宜少於「5」。因此,我們在各坊間民調報告上經常看「細格數據少於5」的表格,其實都是調查「測量與分析基本功」不足的呈現。
▲ 黃珊珊透過 KPTV 發布內參民調。(圖/翻攝 KPTV)
【民調資訊】
-
解讀日期:2023 年 12 月 24 日
-
民調日期:2023 年 12 月 16 日至 17 日
-
民調主題:2024 總統選舉(無正式名稱)
-
報導機構:中國時報、風傳媒等
-
執行機構:求真民意調查股份有限公司
-
調查地區:戶籍於全國 22 縣市且年滿二十歲以上成年人
-
樣本/誤差:1225 人(市話 861 份;手機 364 份),在 95.0% 的信心水準下,抽樣誤差在正負 2.80 個百分點之內
責任、核稿編輯/宋思彤